From Reading to Perceiving
The Quiet Revolution in How AI Understands the World


The Sensory Revolution
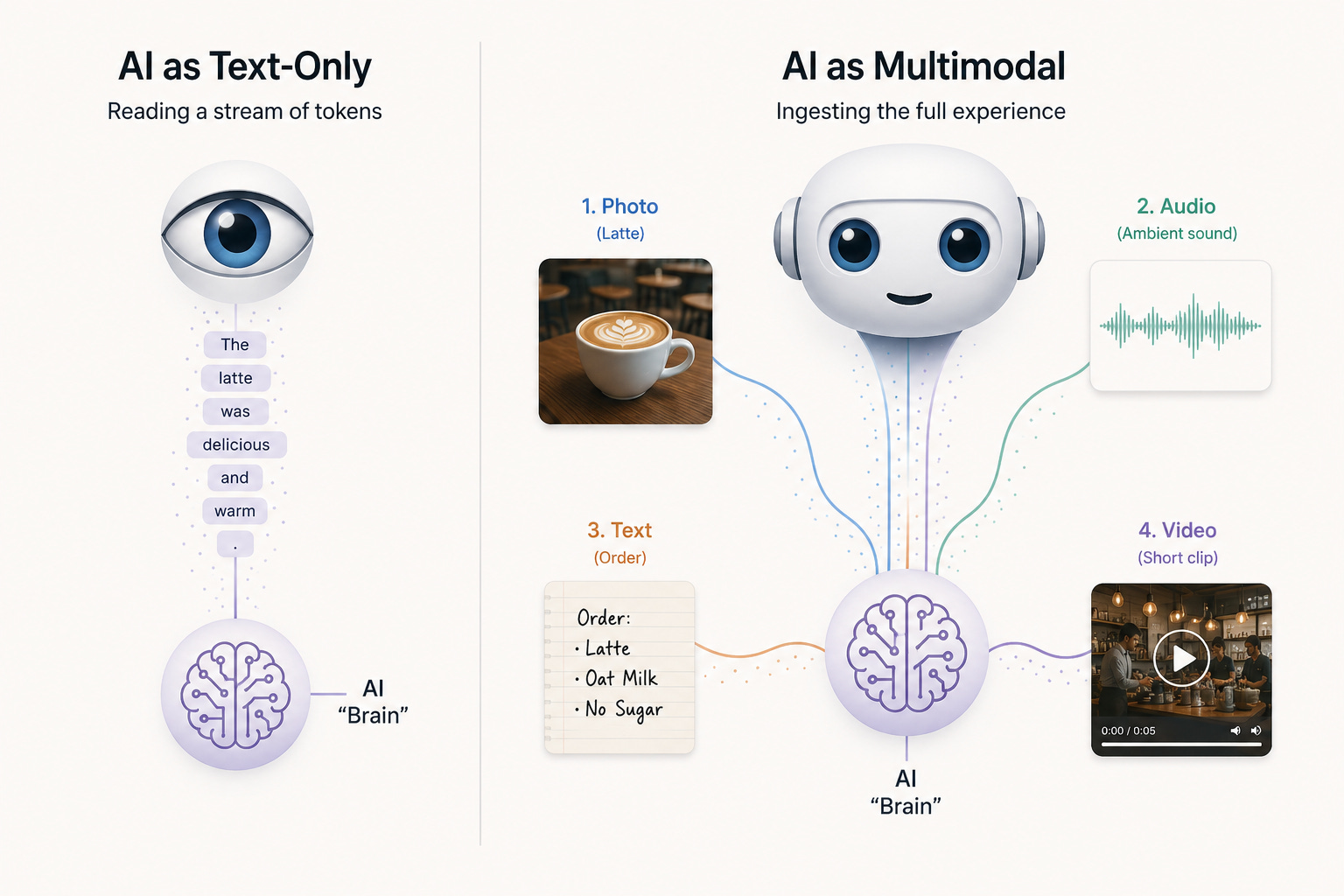
Close your eyes for a moment and try to recall a recent memory, say, the last time you walked into a coffee shop. What comes back is not a paragraph of text. It’s a composite: the smell of espresso, the murmur of overlapping conversations, the warmth of a cup in your hand, the half-glance of a barista who recognized you. Human intelligence is not a reading comprehension exercise. It is a continuous fusion of sight, sound, touch, and language, all streaming together into a single, coherent understanding of the world.
For most of its history, artificial intelligence has been doing the equivalent of reading the menu with the lights off.
That is finally changing. Multimodal AI, systems that can process and relate information across text, images, audio, and video simultaneously, is the most consequential shift in machine intelligence since the transformer itself. It marks a transition from machines that read the world to machines that perceive it. And while the popular conversation still revolves around chatbots and clever prompts, the deeper story is that AI is growing senses.
The Evolution of AI’s Senses
To appreciate where we are, it helps to remember where we started.
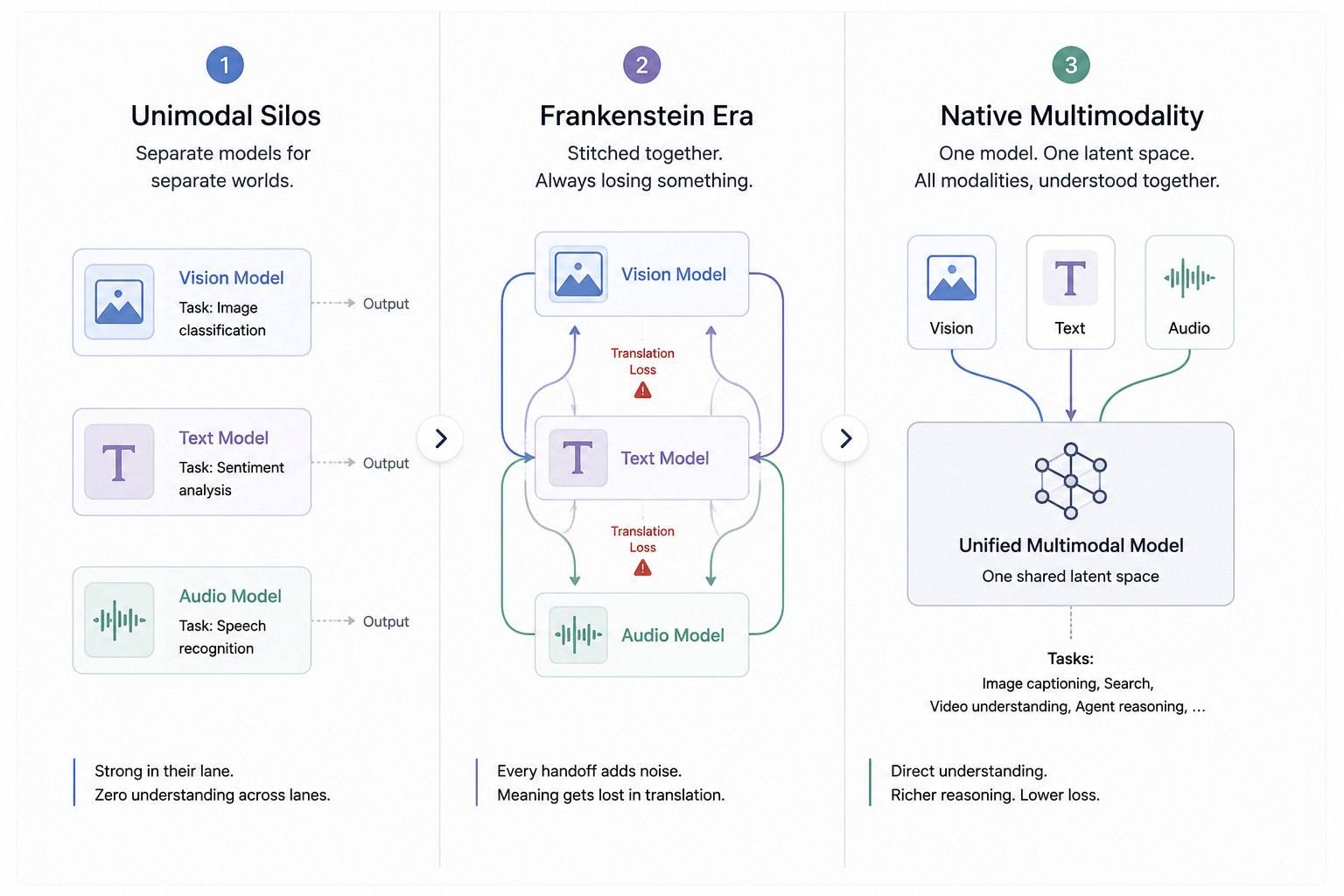
Phase 1: Unimodal Silos. For decades, AI was a collection of specialists who never spoke to each other. Optical Character Recognition systems could digitize a printed page but had no idea what the words meant. Convolutional Neural Networks, popularized by AlexNet’s 2012 ImageNet upset, could identify a cat in a photo but could not write a sentence about it. Speech recognition pipelines transcribed audio into text and then handed off to entirely separate systems. Each model lived in a sealed silo, mastering one modality and remaining utterly blind to the rest. A medical imaging model could spot a lesion; reading the patient’s chart was someone else’s job, usually a human’s.
Phase 2: The Frankenstein Era. As large language models matured, engineers began stitching the silos together. A vision model would describe an image in text, hand that text to an LLM, and the LLM would reason about it. Early visual question-answering pipelines worked this way. So did the first wave of “GPT-4 with vision” demos. The trick worked, but it was duct tape. Information leaked at every seam. A vision model that captioned a photograph as “a woman holding a glass” would strip away whether she was celebrating or grieving, whether the room was lit by candlelight or fluorescent tubes, whether the glass was raised or lowered. The downstream LLM then reasoned about a flattened, dehydrated description of reality. Latency stacked up across each model handoff. And subtle cues — sarcasm in a tone of voice, irony in a facial expression — were lost in translation between systems that had never been introduced.
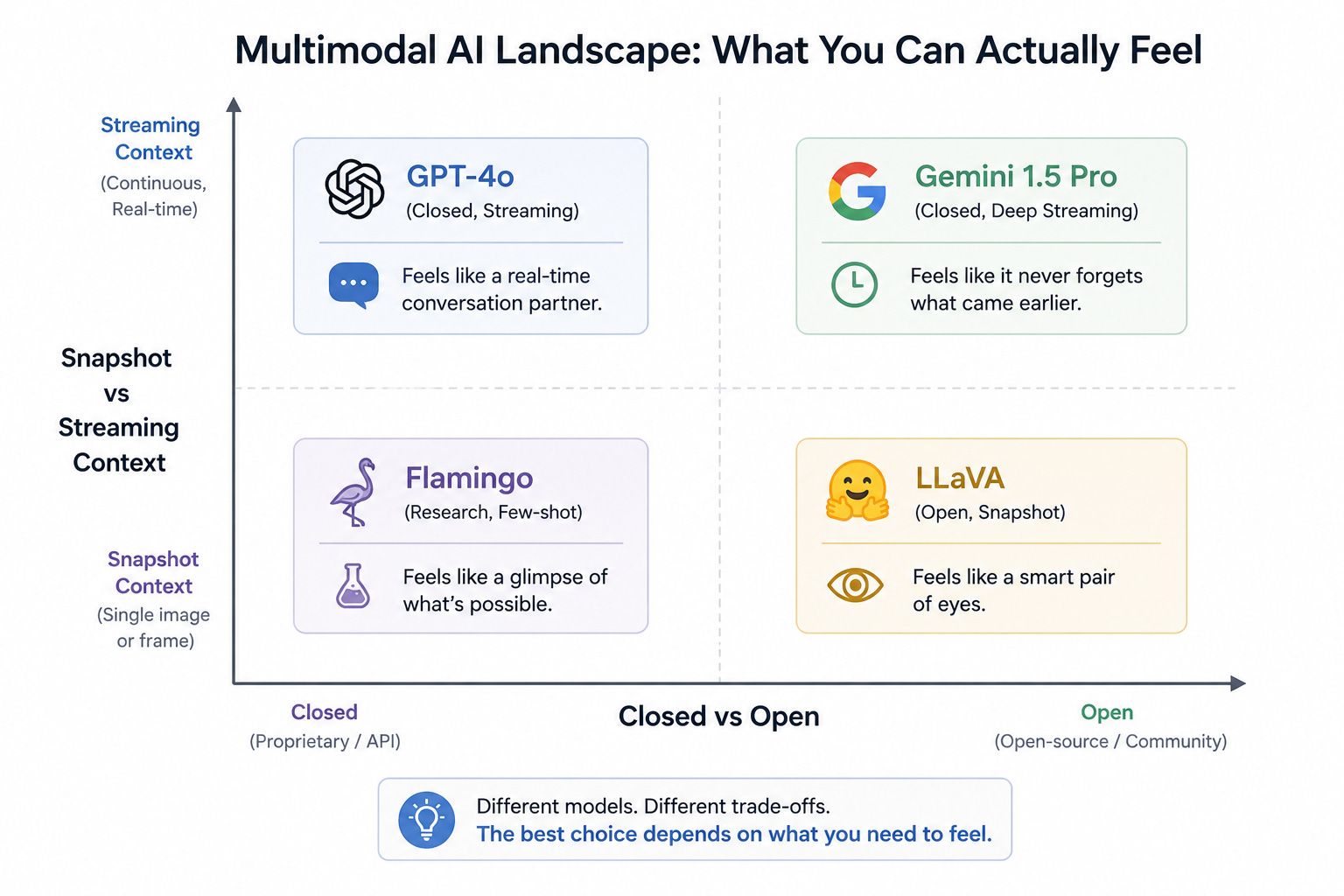
Phase 3: Native Multimodality. The current era began when researchers stopped bolting models together and started training a single model on all data types at once. Pixels, waveforms, characters, and frames are tokenized into a common representation and learned jointly from the start. Google DeepMind’s Flamingo, introduced in 2022, was an early proof point. OpenAI’s GPT-4o (”o” for “omni”), released in May 2024, made it mainstream — a single neural network handling text, audio, and vision end-to-end with response times measured in hundreds of milliseconds. Google’s Gemini 1.5 Pro pushed the boundary on context, ingesting hours of video or millions of tokens of mixed-modality material at once. The model is no longer a committee. It is one mind, with multiple senses.
Why We Actually Need This
It would be easy to dismiss multimodality as a feature upgrade — nice to have, but not transformative. That misreads the moment.
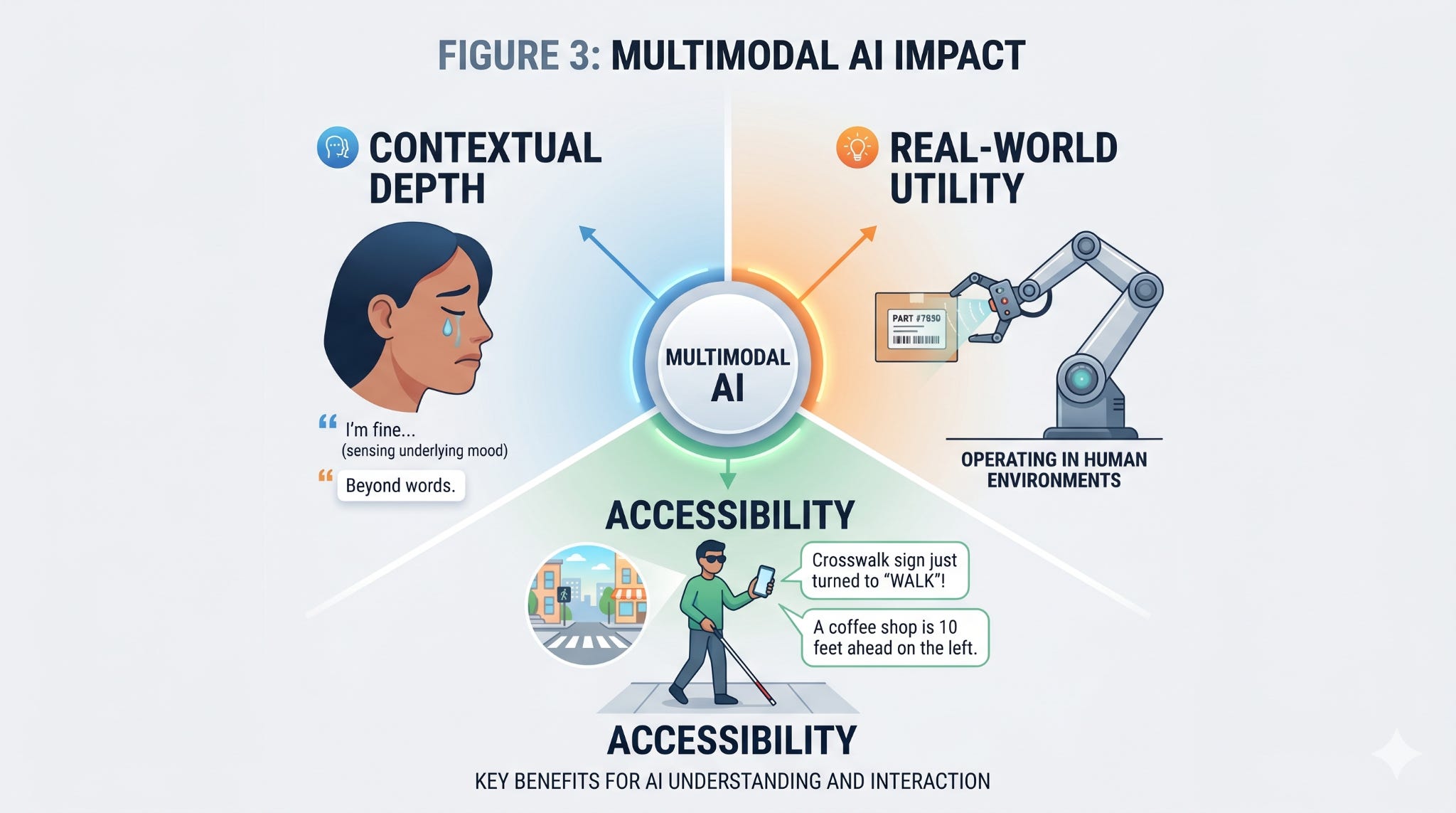
Consider contextual depth. A purely text-based assistant reading the sentence “I’m fine” has no way to know whether it was typed cheerfully or through tears. A multimodal system that can also hear the speaker’s voice, see the slumped posture in a video frame, or notice the time stamp at 3 a.m. has access to the same signals a human friend would use. Communication is not just words; it is the vibe around the words. Until AI can perceive that vibe, it will keep producing answers that are technically correct and emotionally tone-deaf.
Consider real-world utility. A radiologist does not diagnose from a scan alone — she reads the image alongside the patient’s history, lab results, and prior notes. A multimodal model can do the same in a single pass, correlating a faint shadow on a CT scan with a line buried in a discharge summary from three years ago. In robotics, the implications are even sharper. A warehouse robot that can see a cluttered shelf, hear a spoken instruction (”grab the blue one on the left”), and read a printed label at the same time can operate in human environments in a way that no unimodal system ever could. This is the foundation of what researchers at companies like Figure and Physical Intelligence call vision-language-action models — robots that don’t just execute commands, but understand them.
Consider accessibility. For someone who is blind, a multimodal AI that narrates the visual world in real time is not a parlor trick — it is a prosthetic for sight. For someone who is deaf, live transcription with speaker identification and emotional inflection is closer to actual hearing than anything that came before. Be My Eyes integrated GPT-4 with vision in 2023, and early users described it less as a tool and more as a witness. The accessibility frontier is one of the most underdiscussed but most morally significant applications of multimodal AI.
The Secret Sauce: A Shared Vector Space
The technical move that makes native multimodality work is deceptively simple to describe and fiendishly hard to execute.
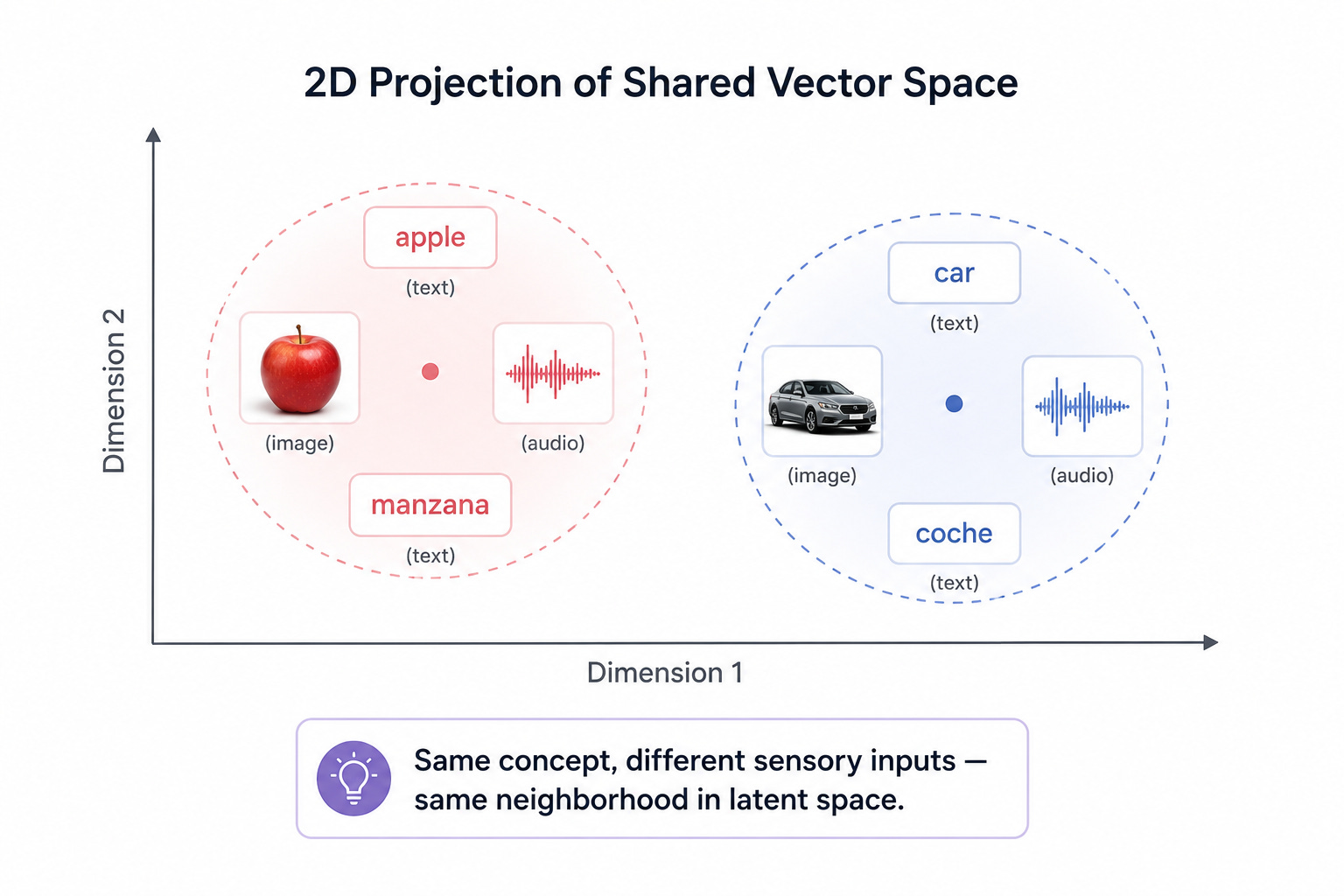
When a modern multimodal model encounters the written word “apple,” it converts that word into a vector — a long list of numbers — that lives at a particular coordinate in a high-dimensional space. When the same model encounters a photograph of an apple, it converts that image into a vector too. The training objective forces both vectors to land in roughly the same neighborhood of that space. The model learns that the word “apple,” a picture of a red Fuji, the sound of a crunch, and a video of someone biting into one all point to the same underlying concept.
This shared embedding space is the closest thing AI has to a unified mental representation. It is what allows a model to answer the question “what’s wrong with this photo?” with a sentence that genuinely engages with the image, rather than a guess pieced together from a stripped-down caption. It is also what allows reasoning to flow seamlessly across modalities: a model can read a math problem, see a hand-drawn diagram, hear a spoken hint, and weave all three into a single chain of thought.
The difference between a glued architecture and a native one is the difference between a translator and a polyglot. A translator who speaks French and English in series will always be slower and more lossy than someone who simply thinks in both languages. Native models think in pixels, words, and sounds at once. They are faster because they skip the handoffs. They are more nuanced because nothing gets compressed into an intermediate text bottleneck. And they are better at reasoning because their internal world model includes the textures of reality, not just descriptions of it.
The Current Landscape
The frontier is moving fast, and it is moving on multiple fronts at once.
OpenAI’s GPT-4o is the consumer face of native multimodality. It can hold a real-time voice conversation with the warmth and timing of a phone call, look through a smartphone camera, and read a screen — all without switching modes. The “o” matters: it is one model, not a relay race.
Google’s Gemini 1.5 Pro went in a different direction, prioritizing massive context. It can ingest a feature-length film and answer detailed questions about a single shot in the third act, or process a multi-hour podcast and trace a callback to something said ninety minutes earlier. The implication is profound: multimodal context is no longer a snapshot, it is a stream.
In the open-source world, LLaVA — Large Language and Vision Assistant — has become the workhorse for developers who want to build multimodal applications locally. It is the model researchers and indie builders reach for when they need vision-language capability without an API bill, and it has spawned an entire ecosystem of fine-tuned variants for everything from document understanding to medical imaging.
Flamingo, the DeepMind system that helped open the door, remains historically important for a different reason: it demonstrated few-shot visual learning. Show Flamingo a handful of image-text examples, and it could generalize to a new visual task without retraining. That capability, learning from a few examples on the fly, is now table stakes for serious multimodal systems.
What Comes Next
The trajectory points toward AI that is not just multimodal but ambient. Real-time multimodal assistants — already visible in early form on smartphones and in smart glasses — will fade into the background of daily life, perceiving what their wearers perceive and offering help without being asked. Autonomous vehicles will fuse camera, radar, and language-based map updates in a single model rather than a stack of brittle subsystems. Smart-home systems will stop responding to wake words and start responding to context.
The deeper change is philosophical. For sixty years, the dominant metaphor for machine intelligence has been the symbol-pushing logician — a system that reads, reasons, and writes. Multimodal AI replaces that metaphor with something closer to a creature. Creatures have senses. They notice. They are continuously in conversation with a world that is richer than any text could ever capture.
The systems we are building now are still rough, still hallucinatory, still occasionally confidently wrong. But for the first time, they share something with us beyond language: they perceive. And technology that perceives, rather than merely processes, will feel less like a tool and more like a presence. That distinction, small in description, immense in lived experience, is the real revolution underway.
 | A guest post by
|
 | A guest post by
|